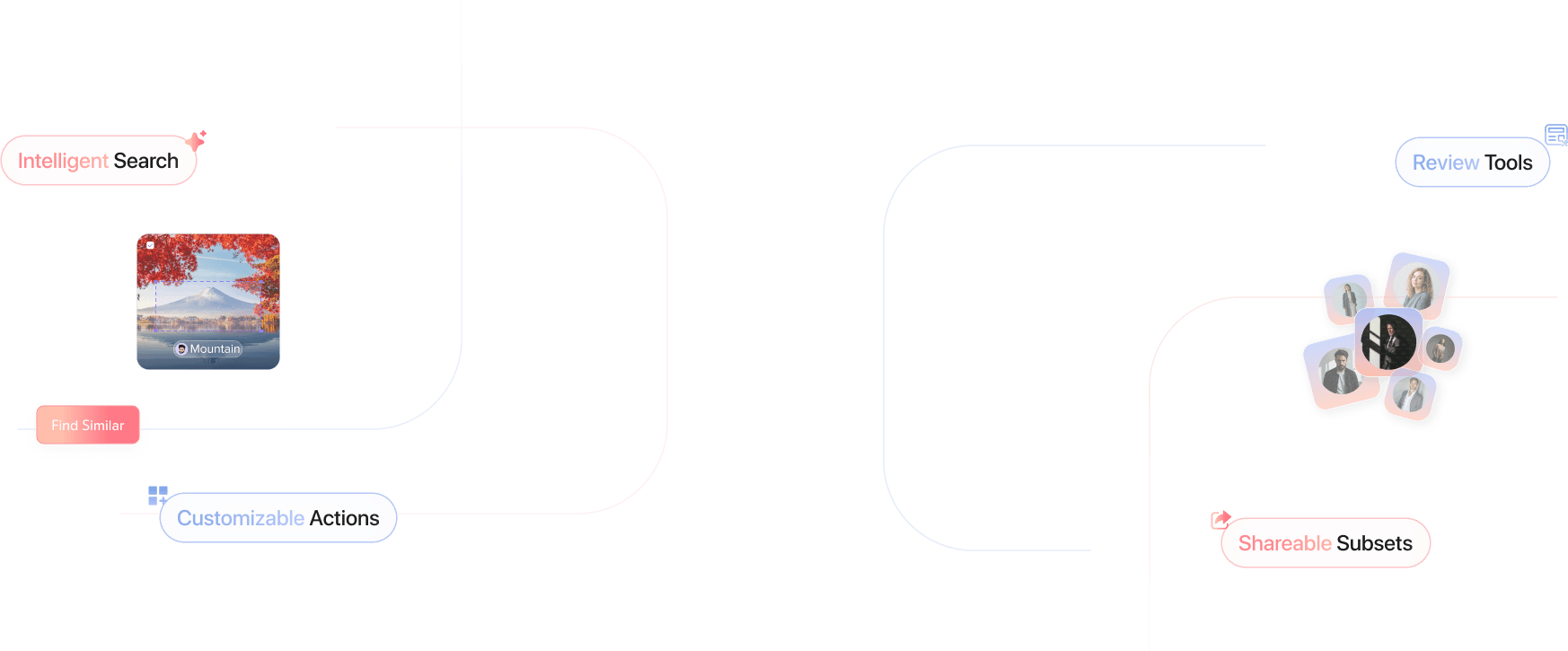
Enhance Model Performance with Less but High-Quality Data
Databrewery helps you prioritize and refine high-value datasets to improve model capabilities. With advanced search, data visualization, vector & traditional search, our platform ensures your models train smarter and perform better
IntelligentSearch
Find, Filter & Refine Data for
Advance ModelLearning
Use vector-powered similarity and natural language search to explore multimodal data- chat, images, videos, and audios. Filter annotations, predictions, and metadata to quickly find, prioritize, and label high-value data for better model performance.
ScaleYour Dataset withAI
Single-Shot Labeling
Tag a single data point, and let advanced algorithms detect patterns to automatically label similar instances across your dataset. Reduce manual effort while ensuring consistency and efficiency.
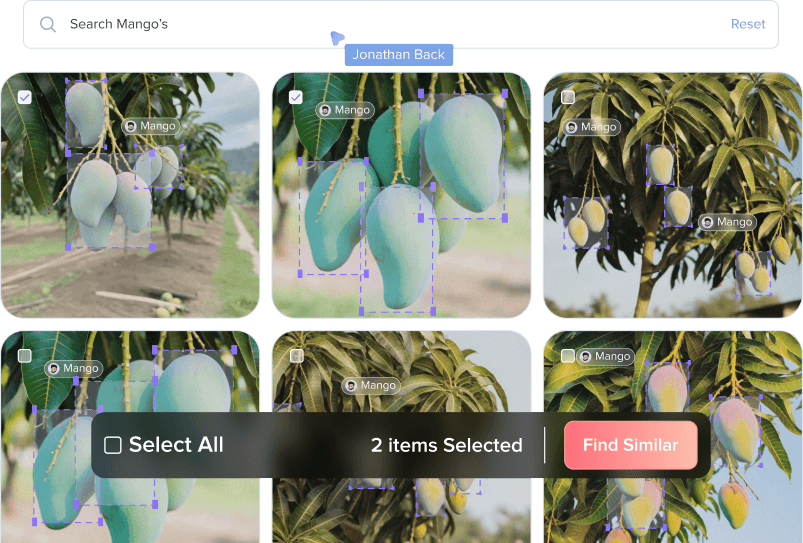
Automated Bulk Classification
Take advantage of natural language search, similarity search, and vector embeddings to automatically mine, categorize, and cluster relevant data. Select in bulk seamlessly, with the option for human review to maximize accuracy.
AutomatedModel Diagnostics
Build high-performance models by identifying and correcting errors in training data. Perform deep error analysis to detect misclassifications, diagnose root causes, and refine datasets with targeted improvements. Continuously evaluate and compare datasets, hyperparameters, and model iterations to enhance accuracy and reliability.
Quality Control & Data Validation
Review and validate dataset quality using search tools. Use vector search to detect patterns, find similar errors, and correct them efficiently. Approve, reclassify, or reject data while providing direct feedback to annotators for consistent improvements.
CollaborativeData Sharing
Select specific data subsets and share them securely with teams or partners through direct links. Enable smooth collaboration without extra software or complex permissions
Our IPA Workflows have become 5x faster due to innovative workflows designed by Databrewery Team.
Databrewery helped us scale our AI data operations efficiently.